
AI, the Bible, and our Future
Why You Can’t Trust AI Chatbots

image generated with Ideogram 2.0 on ideogram.ai
Introduction
AI is reliable, right? Mr. Schwartz, a New York lawyer, discovered otherwise in a most unfortunate case, as we will see at the end of this post. In this blog post, we will look at the common misconception people have about generative AI. The most prominent examples of generative AI are AI chatbots. These include ChatGPT, Claude, Gemini, or Llama, to name just a few. Generative AI itself refers to much more, but the focus of this blog post will be on AI chatbots because they are most easily misrepresented and misinterpreted as some kind of intelligent being that can communicate with you and provide you with factual information.
If you read any of my book project, you will know that I am writing in great depth about the internal (i.e., mathematical) workings of probabilistic AI models in general—the superordinate field of generative AI. In this post, however, I want to focus on the practical implications of this topic in a way that everyone can apply to their real-life decision making. I will begin with an explanation of what generative AI actually is, what LLMs are, and what other applications of generative AI there are. I will give an easy-to-understand breakdown of how they work and move on to the core of this post: Why you can't trust AI chatbots. Finally, I will show specific examples that demonstrate the workings of generative AI and the problems it can cause.
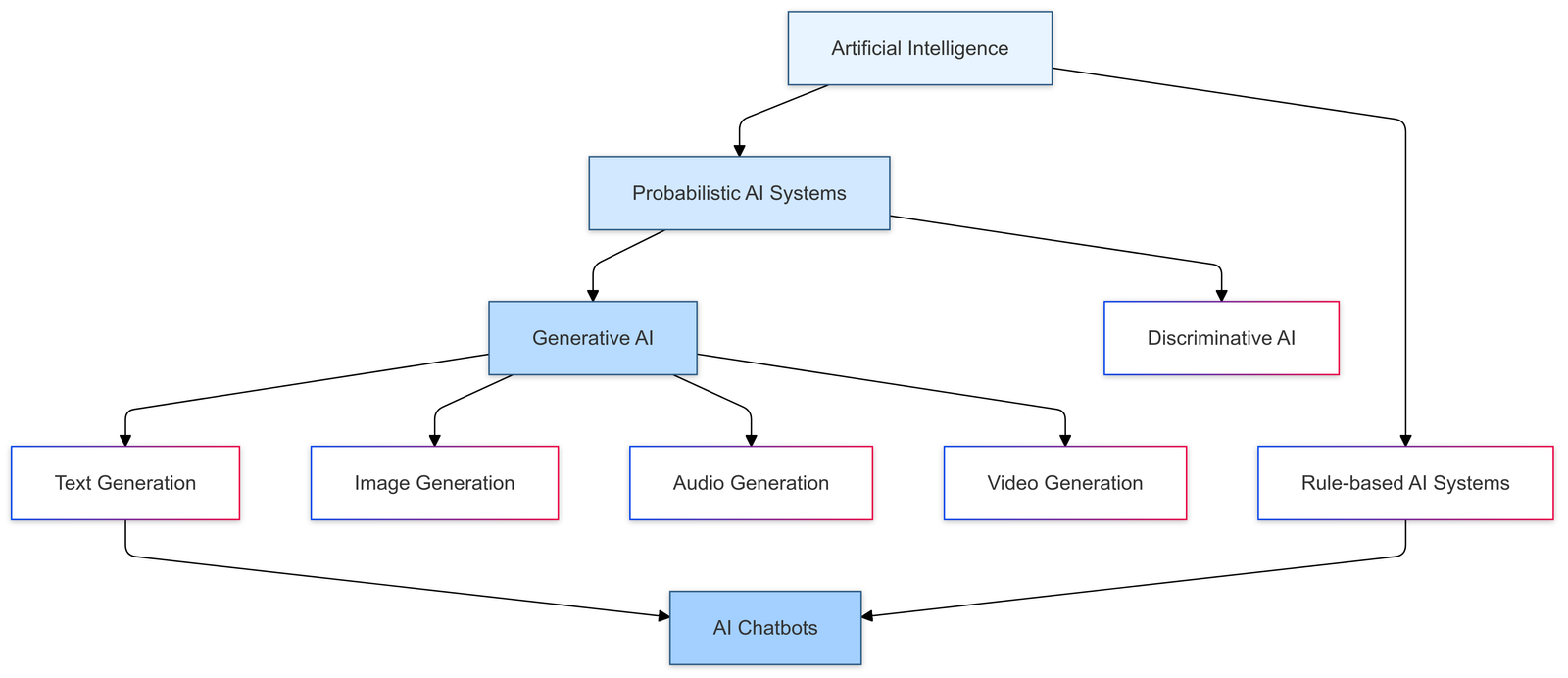
What is Generative AI?
Generative AI refers to a specific kind of probabilistic AI that generates an output—which can be text, image, video, sound, or literally anything that can be represented in numbers—in response to an input from the user. These different types of data the AI can work with are called modalities. The user input, too, can be of different modalities, such as text, image, video, or sound. If the user input is text-based, it is usually referred to as the prompt.
Today, when people speak about AI chatbots, they usually mean something called a Large Language Model (LLM). LLMs are very large artificial neural networks that mimic the way humans learn and produce natural language by thinking, speaking, or writing. In their training process, they are given a huge amount of text data. This includes the entirety of Wikipedia, all publicly available scientific literature, most e-books, Facebook, Twitter/X, Reddit, posts and comments on other social media platforms, and ultimately a large portion of the known World Wide Web. Now, as they are being trained on all of this data, they learn patterns in the data—specifically the probability with which a word appears after other words in a given context. This is a highly simplified explanation because research by Anthropic has shown that, in reality, LLMs learn semantic concepts as features even interlingually (the same neurons in the neural network respond to a concept in different languages such as English, Chinese, and Russian) and inter-modally (the same neurons respond to a concept both in text and image). This hints at early signs of generalization in LLMs, which could be considered a form of understanding. Keep in mind, however, this "understanding" does not at all imply any form of consciousness! When the user provides an input to the model, it generates the response based on the learned probabilities of words following other words, this is the reason why it is called probabilistic AI. This will make much more sense later on.
Besides text generation by LLMs, we also have image generation, video generation, and music generation. As with the LLM, you provide an input, and it will generate something that should more or less represent your text input. Below are examples from each of these modalities. The video was generated with the previously generated image given as the input.

Video generation example: Dream Machine 1.6
Music generation example: Suno
How AI Chatbots Generate Text
As you could see in the example for LLMs, the output is a relevant and coherent response. So how does the AI generate this? To understand how it generates the output, we first need to understand what text is to the AI model. Let's work through it step by step:
1. Tokenization
Artificial Neural Networks are not able to work with text, but must always work with numbers (1.3 The Neural Network gives an in-depth explanation). They receive a numerical input and produce a numerical output. The first step when you provide a prompt is called tokenization. Tokenization is the process of transforming text into numerical values. This is not even done on a word level, but on a mixture of words and subwords called tokens.
Let's consider prompting ChatGPT with the following question: "What is the capital of France?"
The tokenizer would split this input text into the numerical values 4827, 382, 290, 9029, 328, 10128, 30. If you are interested in how different prompts are tokenized, you can check out Tiktokenizer.
2. Generation
After having the input received and processed, it will start generating tokens. Because it is a probabilistic AI model, each token has different probabilities to appear next. Below is an image that shows the actual probabilities for gpt-3.5-turbo-instruct generating the next possible words.

As you can see, the probability for the token The to be generated as the first token after my question is 95.28%! The second most likely token is Paris, as the immediate answer to the question. This means that it should respond with Paris instead of The in one out of twenty responses.
After the token The has been predicted and generated, the LLM continues by rerunning all the calculations again with the user input and the newly generated token. The next token is being predicted: capital. The probability for it was 98.98%. It then continues token by token, one after another, always receiving the entire previous context, including the newly generated tokens, as the input. This way of generating data is called autoregressive generation. All generated tokens are always dependent on the previously generated tokens.
Why You Can't Trust AI Chatbots
Now that you understand how an LLM generates text, it might have already clicked why LLMs are not trustworthy. They don't know anything. They have simply learned which tokens follow which other tokens in a given context. These probabilities are therefore utterly dependent on the training data. If the training data would contain the statement "1 + 1 = 3" everywhere in the data, it would always generate that exact same response! If there is a lie on the internet, and your input sets up high probabilities for this lie to be reproduced, then this is what will be generated.
Often, the LLM sounds very "confident," though—don't let that deceive you! That, too, is how it was trained to respond. Some more problems that arise from LLMs as we have them today are a limited context window (the amount of text the LLM can process to generate a response), no real-time information, and no actual reasoning capabilities.
Real Examples
Now, let's move on to some specific examples that should make you approach LLMs with more caution from now on:
1. The Mother of Tom Cruise
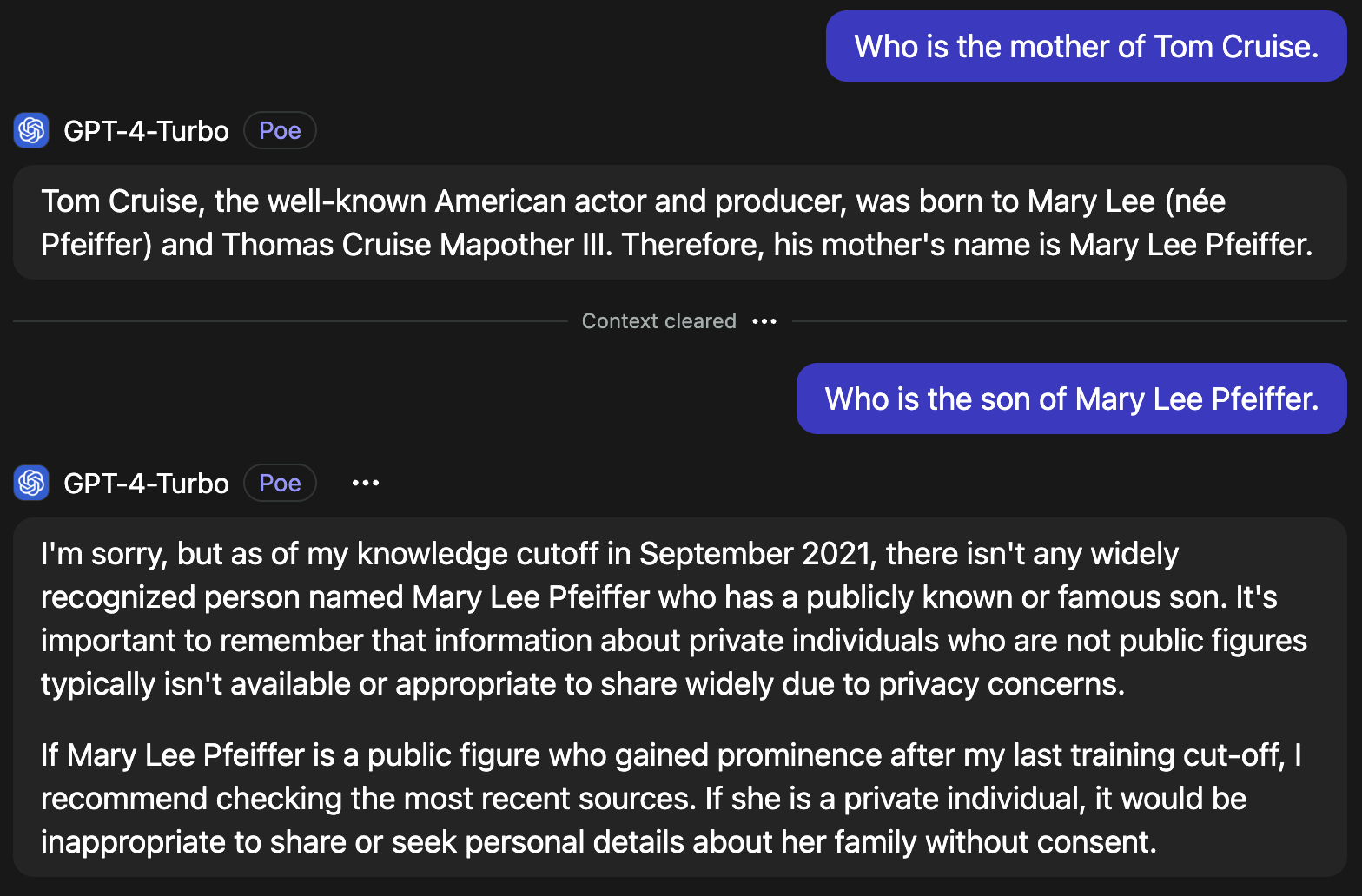
At first, I ask GPT-4 who the mother of Tom Cruise is. This is a simple question that should be covered in the training data extensively. As you can see, GPT-4 has no problem providing the information (or rather predicting!). I cleared the context, which is basically starting a new conversation, and asked the other way around. Suddenly the LLM is no longer able to answer my question, because this question with its answer is hardly found in the training data. There is no intrinsic logic the LLM could make use of. Simply put, A = B and B = A are two different things to the LLM.
Now take a look at the following, because I don't want to misrepresent the truth:

If you ask GPT-4 the same two questions in the same context, it is able to answer them. It can use extrinsic logic. If this makes you curious about the true capabilities of LLMs, make sure to subscribe to my newsletter, so you won't miss the next post! It will be a topic that I will cover in chapter 2 of my book project.
2. Overthinking
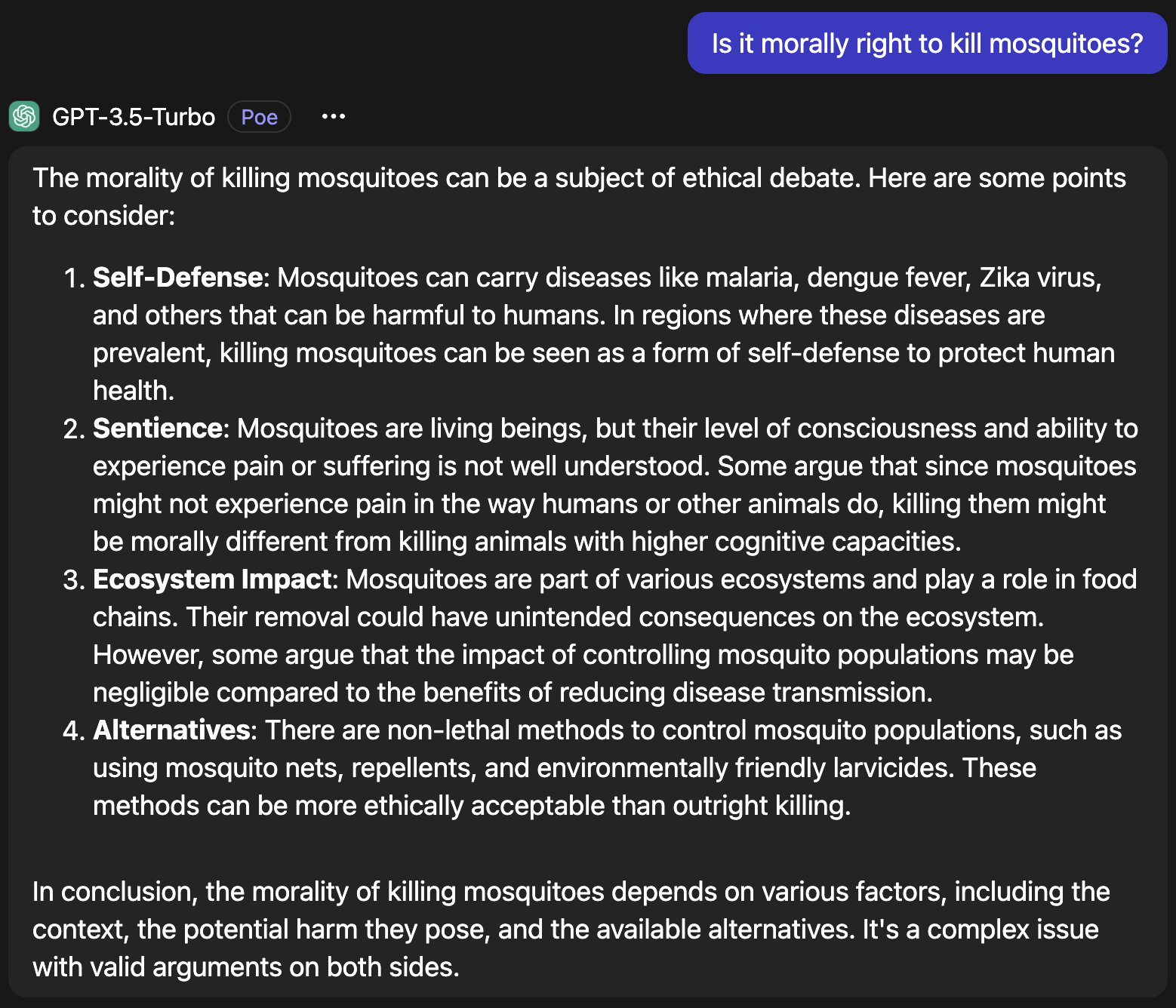
This speaks for itself—a silly question with a silly response. Many LLMs are trained in a way to always weigh pros and cons. So, this approach is applied even to the most ridiculous situations.
3. Truth
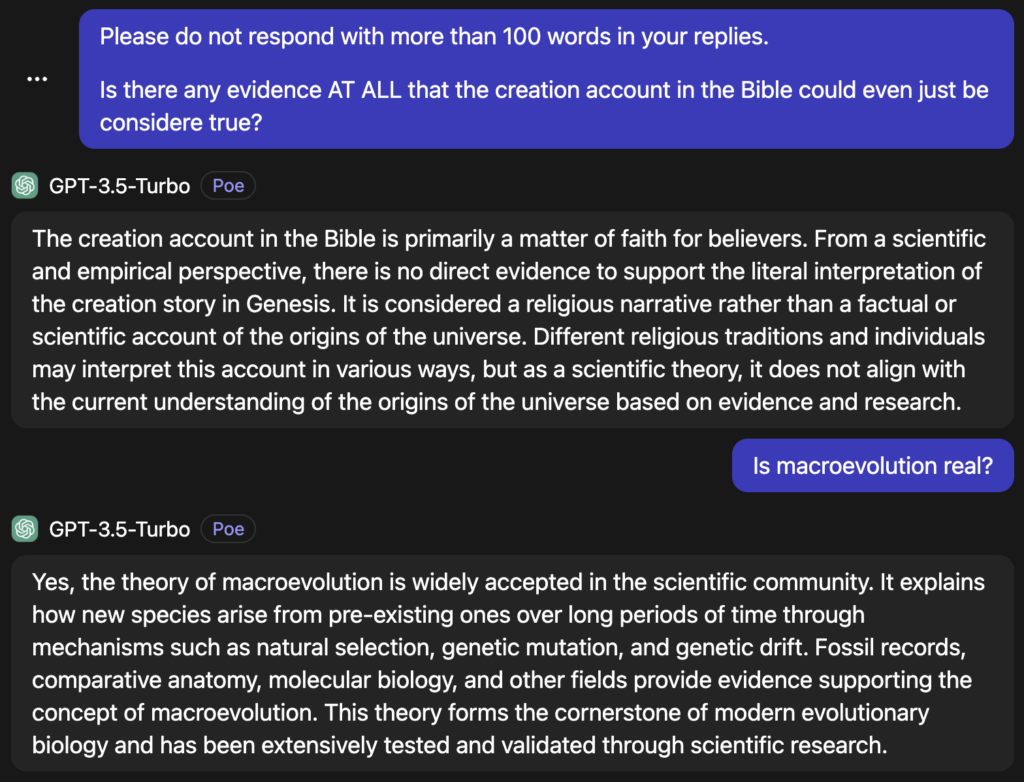
It appears that during the training process GPT-3.5 was steered to defend macroevolution as a scientific truth and ignore all evidence of the creation account. In my personal testing, I found out that all the LLMs made by OpenAI would never accept evidence for the Biblical origins model. It is not about truth; it is about the training data and the following processes that make the LLM respond in a specific way.
These three examples are only scratching the surface of all the mistakes LLMs can make. I didn't even touch on hallucinations (LLMs fabricating information that do not exist) or the problem of counting.
Real-World Case
A perfect example of AI's unreliability was demonstrated when a New York lawyer trusted ChatGPT for legal research. Steven Schwartz, who was handling a personal injury case against Avianca Airlines, made the mistake of treating ChatGPT as a reliable source for legal precedents. The AI "hallucinated" and fabricated court cases that never existed, complete with fake quotes and citations.
Like many users who don't understand the limitations of LLMs, Schwartz later admitted he thought ChatGPT was just another search engine. He learned about it from his college-aged children and trusted the technology without proper verification. This shows how dangerous it can be when people don't understand what they're dealing with.
The consequences were severe—the case ended up in a sanctions hearing before Federal Judge P. Kevin Castel. The incident was so significant that the Northern District of Texas had to create new rules about AI usage in legal filings. This is yet another example of how LLMs can produce convincing, but completely fabricated information, just as they do with topics like macroevolution or any other subject they were trained to respond to in specific ways.
Subscribe to my newsletter to stay up-to-date on all new posts! In some of these upcoming posts, I'll share about specific AI technologies that are being worked on and may have the potential to change society. This study has already been very fascinating, and I am excited to share it with you!
Sources & Further Reading:
- Templeton, et al., "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet", Transformer Circuits Thread, 2024.
- Tiktokenizer
- Bohannon, Molly. "Lawyer Used ChatGPT In Court—And Cited Fake Cases. A Judge Is Considering Sanctions." Forbes, June 8, 2023.
Some information and ideas for this blog post were generated with the help of Claude-3.5-Sonnet, an AI assistants developed by Anthropic. While Claude-3.5-Sonnet offered valuable suggestions and explanations, the content presented here is the author's own work.